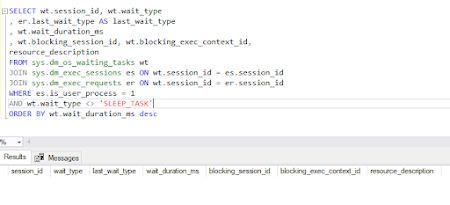
IO Usage at the Database Level and file level
IO Usage at the Database Level We can build out further on this information and present the data in a more usable format and provide exactly what we need vs. what the developer of the DMV/DMF may have foreseen it used for by writing our own query with it incorporated into it. WITH IO_Per_DB AS (SELECT DB_NAME(database_id) AS Db , CONVERT(DECIMAL(12,2), SUM(num_of_bytes_read + num_of_bytes_written) / 1024 / 1024) AS TotalMb FROM sys.dm_io_virtual_file_stats(NULL, NULL) dmivfs GROUP BY database_id) SELECT Db ,TotalMb ,CAST(TotalMb / SUM(TotalMb) OVER() * 100 AS DECIMAL(5,2)) AS [I/O] FROM IO_Per_DB ORDER BY [I/O] DESC; The above query now displays total MBPs and percentage of IO across entire SQL Server per database. If we need to few this in a more detailed perspective , i.e. from the data file view vs. the database, ensuring we identify prospective high IO areas that could become a bottleneck, we could use the following query: WITH IO_Per_DB_Per_File AS (SELECT DB_NAME(dmivfs.database_...