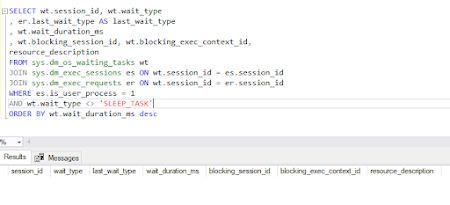
Unlocking SQL Server Performance: A Dive into Dynamic Management Objects (DMOs)
In the intricate world of SQL Server performance optimization, the quest for identifying and resolving bottlenecks often feels like a detective's pursuit. Shared resources such as CPU, memory, and disk subsystems can all play a role, making it challenging for Database Administrators (DBAs) to pinpoint the root cause accurately. The Quandary of Misdiagnosis A common pitfall is mis-attributing sluggish query performance to a generic need for more CPU power or faster disks, without delving into the specifics of the performance bottleneck. For example, simply adding more CPU capacity might not be the silver bullet if the majority of response time is tied to I/O waits rather than CPU utilization. Dynamic Management Objects (DMOs): The Game Changer Enter Dynamic Management Objects (DMOs), the silent heroes in the realm of SQL Server performance tuning. DMOs offer a more systematic approach to troubleshooting by enabling DBAs to swiftly narrow down their focus. One powerful application is